WWWの仕組み
【本節の目的】
WWW(World Wide Web)の要素技術の概略とWWWの仕組みを理解することです。
World Wide Web (WWW) を構築している技術と構成要素
皆さんが親しんでいる WWW (Web, ウェブ) は、
比較的簡単な仕組みで成り立っています。
WWWは、基本的に以下の技術と構成要素から成り立っています。
- URI (Uniform Resource Identifier)
- HTML (HyperText Markup Language)
- Webブラウザ (Web Browser)
- Webサーバ (Web Server)
URI (Uniform Resource Identifier)
インターネット上にあるすべてのリソース(資源、ファイル)を、
統一的に一意な名前で呼ぶ仕組みです。
URIは、リソースの「場所」を指定するURL (Uniform Resource Locator) と、
「名前」を指定する URN (Uniform Resource Name) を合わせた概念になっています。
ただ、URN が現実的に利用可能ではないので、URL とほぼ等価です。
URI = URL + URN ≒ URL
URIは、「スキーム」「サーバ部」「パス部」で、構成されています。
例えば、下記のURIのそれぞれは、
http://www.kumamoto-u.ac.jp/kiss/G/top.html
以下のようになります。
- スキーム(プロトコル, 手順): http
- サーバ部: www.kumamoto-u.ac.jp
- パス部: /kiss/G/top.html
それぞれの構成要素は、おおよそ以下のようなことを表わしています。
- スキーム (プロトコル、手順)
- URIが、どのような仕組みで名前をつけるのかを表わします。
これにより、リソースを取得する手順(プロトコル)が決まります。
代表的な http (HyperText Transfer Protocol) は、
後述する HTML などの文書を受信するときに用いる(通信)手順です。
- サーバ部
- リソース(ファイル)が格納されている(リソースを提供してくれる)
マシン(PCを含む)を表わします。
- パス部
- サーバ上のリソース(ファイル)を表わします。リソースは通常、
リソース(ファイル)が格納されている階層的なディレクトリ(フォルダ)名と、
狭い意味のリソース(ファイル)名を組み合わせた、
「パス」で表わします。
HTML (HyperText Markup Language)
文書の各部分を意味の塊(かたまり)として考え、
意味の塊を「タグ」で囲んで表現する (マークアップ(Markup)する)
文書記述言語の一種です。
「タグ(tag)」とうのは、もともと「荷札」や「値札」のことですが、
ここでは、「< >で囲まれた決まった文字の並び」のことです。
このタグにより、文書の構成を指定したり、表示形式を指定したりします。
また、「文書記述言語」というのは、
コンピュータ(PC)が理解できる言語(言葉)ですが、
いわゆる「プログラム言語」とは異なり、
コンピュータに計算などの処理をさせるのではなく、
作者の意図した文書の構造を表現するための言語です。
「HyperText (ハイパーテキスト)」というのは、文章の中に、
他の文章やデータの位置情報 (HyperLink; ハイパーリンク) を埋め込み、
複数の文書を相互に連結できる仕組みのことです。
皆さんは、既に Webブラウザのリンク(ボタン)をクリックして、
複数のWebページ(文書)が連結されているのを利用していますよね。
つまり、HTMLというのは、「複数の文書を相互に連結する機能をもち、
タグにより文章各部の意味付けを行うWWW用に開発された文書記述言語」
ということになります。
ただ、上記の文章だけの説明では、HTMLについて良く分らないと思いますが、
今の段階では、ぼやっと自分なりに想像してもらえば結構です。
Webページは基本的にこのHTMLで記述されていますので、このHTMLを中心に、Webページ作成に関する各種技術を習得していきます。
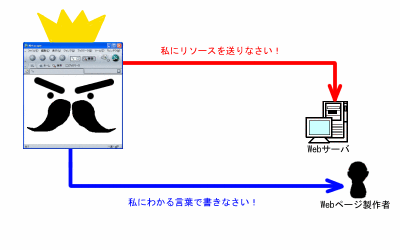
Webブラウザ (Web Browser)
言わずとしれた、Netscape Navigator や Internet Explorer
に代表されるWWW閲覧ソフトウェアのことですね。
実は、このWebブラウザこそが、WWW界の王様なのです。
というのも、以下のようにWebブラウザの機能次第で、
インターネット上のリソースを利用できるかどうかが決まるのです。
- Webブラウザが理解できる形式 (URI) で表示したいリソース(ファイル等のこと)を指示しないと、
インターネット上のリソースにアクセスできない
- Webブラウザが理解できる(記述)言語で書かれた文章やデータでないと、
ブラウザ上で表示されない
- Webブラウザが理解できるプログラム言語で書かれたプログラムでないと、
ブラウザ上で動作しない。
Webサーバ (Web Server)
基本的には、
WWWのクライアント(Webブラウザ)から要求のあったリソース(ファイル)を、
Webブラウザ(の動いているPC)へ送り出す機能をもっているのがWebサーバです。
ただ最近では、Webサーバが複雑な処理をして、
その処理結果をWebブラウザへ送り出すような場合も増えています。
例えば、熊大のSOSEKIのように、
Webブラウザで入力されたデータをサーバに格納したり
(SOSEKIで履修申告をするとサーバに登録されますよね)、
googleのように、検索対象の文字列を入力することで、
Webサーバが対象となるサーバを探し出し、
その文字列を含むWebページを列挙してくれるという具合いです。
WWW動作の仕組み
前節の要素技術の組み合わせで、WWWは構築されています。
Webページを表示する仕組み(流れ)は、おおよそ下の動画のようになります。
(※公開科目では、動画は非表示にしています。)
動画およびその下にある説明文を読んで、
WWWの仕組み (Webページの表示の仕組み)を理解して下さい。
- Webブラウザに、見たい(表示させたい)URIを入力する。
もしくは、見たいリンクをクリックする。
- するとWebブラウザが(最終的にはWebブラウザの動いているPCが)、
指示されたURI(リンクをクリックした場合はリンク先のURI)のサーバに対して、
指定された手順(通常は「HTTP」)で、
パスで示されたリソース(ファイル)を送ってくれるように要求を出す。
- 要求を受けたサーバは、
送信要求を受けたファイルを指示を出したPC(「サーバ」に対して、
「クライアント」と呼ぶこともある)に送信する。
- ファイルを受け取ったWebブラウザは、
HTMLの文法に従いファイル中の文章をブラウザ画面にレイアウトする。
- 受け取ったHTMLファイルが文字情報しかないファイルであればこれで終りだが、
他に画像ファイルや別の文書ファイルが必要であるファイルであれば、
再度サーバにこれらのリソース(ファイル)を要求する。
- サーバから、それらのデータファイルが送られて来たら、
HTMLの文法に従い、先の文字情報とともに最終的なレイアウトを行う。